
:quality(80)/p7i.vogel.de/wcms/17/47/1747dba1351cdbd8759d3d79d6212c00/0131963427v2.jpeg "Industrielle Vernetzung: Damit KI, Automatisierung und IoT ihre Stärken ausspielen können, ist eine weniger komplexe und gleichzeitig effizientere Konnektivität gefragt. 5G RedCap vernetzt Millionen industrieller Endgeräte. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/3f/5f/3f5f3a0588397d2a70b6ec1345e7035c/0131917355v1.jpeg "Bild links: vertikale 3D-FeFET-Speicherstruktur mit gestapelten Zell-/Wortleitungsbereichen der neuartigen Transistoren. Bild rechts: REM-Nahaufnahme einer nanoskaligen ferroelektrischen Speicherzelle oder Kondensatorstruktur. Die vom Imec vorgestellten verbesserten FeRAM-Technologien sollen niedrigere Betriebsspannungen durch optimierte ferroelektrische Schichten und höhere Speicherdichte durch vertikale 3D-Integration ermöglichen. (Bild: Imec)")
:quality(80)/p7i.vogel.de/wcms/0b/99/0b9903e11b1cd8e5cdc52384d9177532/0131857635v2.jpeg "Dr. Alexander Noack steht neben dem QRNG-R19-Demonstrator. Dieser Quanten-Zufallszahlengenerator gewinnt echte Zufälligkeit aus Quanten-Vakuumfluktuationen. Auf Basis von intrinsisch zufälligen und unbeeinflussbaren Quanteneffekten werden echte Zufallszahlen mit Bitraten von 4 GBit/s erzeugt. (Bild: Fraunhofer IPMS)")
:quality(80)/p7i.vogel.de/wcms/a5/df/a5dfa5148af04ae072dfbf628009ef89/0131873657v3.jpeg "(Bild: Imec)")
:quality(80)/p7i.vogel.de/wcms/f0/1b/f01bf534ae26f5c6af66cbf13235b87a/0131857321v2.jpeg "AMD hat das in Kalifornien ansässige Startup Mext übernommen. Das von dem Unternehmen entwickelte Speicher-Tiering soll selten genutzte Daten auf NAND-Flash auslagern und so den DRAM-Bedarf in Rechenzentren entlasten. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2f/8c/2f8cbb9ce99efe9167d76bc478ccbbec/0131973200v2.jpeg "Generative KI und Recurrent Networks laufen auf den Photonik-Prozessoren der zweiten Generation von Q.ANT. (Bild: Q.ANT)")
:quality(80)/p7i.vogel.de/wcms/7c/48/7c485d31114d59b3020a89b80f1dbab0/0131965381v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/22/91/2291af437589cf538d2bef1b4683c6c4/0131948656v2.jpeg "Abschied von der Warteschlange: Die Dataflow-Architektur des Mach M100 lässt Datenströme parallel fließen, statt sie in eine klassische Befehlsschlange zu zwingen. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/67/67/6767a778d47ced021875655347ecbc8a/0131948516v2.jpeg "Nordic nRF54L15 Tag: Prototyping-Plattform für Bluetooth Channel Sounding und Edge AI (Bild: Nordic)")
:quality(80)/p7i.vogel.de/wcms/03/14/031429a9de0cf9efcfbcd477e8b2ef02/0131907760v2.jpeg "Das Münchner Landgericht hat in zwei weiteren Patentrechtsklagen gegen das chinesische Unternehmen Innoscience zugunsten von Infineon entschieden. Doch in China befand der oberste Gerichtshof, dass hingegen Infineon ein Patent des chinesischen Konkurrenten verletzt haben soll. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/fc/8a/fc8abb4d63749d997f748520bbb69c2f/0131809996v2.jpeg "Dimensionen im Fokus: Eine vollständige Wheatstone-Brückenschaltung auf einer Fingerkuppe verdeutlicht den hohen Grad der Miniaturisierung der Sensortechnologie von Digid. (Bild: Digid)")
:quality(80)/p7i.vogel.de/wcms/1e/7a/1e7a37663aad5ee011b0f766d44e8ed9/0131765852v2.jpeg "Stromversorgungslösungen für Rechenzentren boomen, entsprechend gefragt sind SiC-Anwendungen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/14/d7/14d7cb77132e76f852e71edf06cc94fb/0131803730v2.jpeg "Tom Trill, CEO von Qualinx, und Dr. Manfred Horstmann, Senior Vice President und General Manager bei GlobalFoundries (Bild: Globalfoundries)")
:quality(80)/p7i.vogel.de/wcms/5b/75/5b758a6d983e2380da34de7bd474d422/0131438570v2.jpeg "AMD Zynq Ultrascale+ MPSoC ZCU102 Evaluierungskit: Ob als fertiges System oder zur Vorevaluierung, die Implementierung eines RISC-V-Softcores auf einem FPGA kann sich mituner schwieriger gestalten als gedacht. (Bild: AMD)")
:quality(80)/p7i.vogel.de/wcms/2e/78/2e789ef76c84f5fcdf02b5697a22f9ab/0131062677v2.jpeg "Zur Stärkung des Portfolios insbesondere mit Blick auf Edge-Cloud-Infrastruktur für KI-Lösungen übernimmt Low-Power-FPGA-Spezialist Lattice Semiconductor den Firmware- und Cloud-Software-Entwickler AMI. (Bild: Lattice)")
:quality(80)/p7i.vogel.de/wcms/d4/1d/d41d81ec84a42b4fd5d732d36d0021ce/0130877962v2.jpeg "Im Element:
Auch fast 40 Jahre, nachdem sich der Elektrotechnik-Ingenieur als Berater für ASIC- und FPGA-Entwicklung selbstständig machte, hält Eugen Krassin immer noch Schulungen und Seminare zur programmierbaren Logik. (Bild: Toby Giessen)")
:quality(80)/p7i.vogel.de/wcms/0f/c4/0fc4f1c68ab438a1b827685f52aac47b/0131898344v2.jpeg "Die Electronica 2026 zeigt Technologien für resiliente Elektronik. (Bild: Messe München GmbH)")
:quality(80)/p7i.vogel.de/wcms/e8/42/e842dfba0064a29978935733ebc89eb0/0131831278v2.jpeg "Während Desktop-Systeme heute standardmäßig mit Exploit-Mitigation-Mechanismen abgesichert sind, fehlen vergleichbare Schutzmaßnahmen in vielen Embedded Devices noch immer. Das macht vernetzte Geräte im Feld zu einem attraktiven Angriffsziel und verschärft den Handlungsdruck für Hersteller. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8b/a7/8ba78f02e76e08a21fe98487faa35225/0131725834v1.jpeg "Die Neugründung eines KI-Sicherheitsinstituts soll insbesondere auf die digitale Souveränität Deutschlands einzahlen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2c/05/2c05adc30b1bb9116c6bc4599cd718a7/0131969461v2.jpeg "Die bewährte Pilot V8 basiert nun auf der neuen, offenen OPERA-Plattformarchitektur von Seica. (Bild: Seica)")
:quality(80)/p7i.vogel.de/wcms/89/19/8919b730db26bf6feaa3b1e8807b74e3/0131933577v2.jpeg "Das Koordinatenmessgerät Leitz Infinity von Hexagon ist mit HoloTop NX des Fraunhofer IPM ausgestattet. Durch die Erweiterung um einen optischen Sensor ist eine flächige, hochauflösende Qualitätsprüfung kritischer Bauteilbereiche wirtschaftlich möglich. (Bild: Fraunhofer IPM)")
:quality(80)/p7i.vogel.de/wcms/41/c8/41c8b2ac5f7c241b160f506d5f961259/0131899009v2.jpeg "Göpel electronic aus Jena kann auf eine 35-jährige Erfolgsgeschichte zurückblicken. Entstanden ist das High-Tech-Unternehmen aus der Abteilung für Mess- und Prüftechnik des VEB Kombinat Carl Zeiss Jena. (Bild: Göpel electronic)")
:quality(80)/p7i.vogel.de/wcms/c2/db/c2db602ca0623a9c9f2a67e68394bcf4/0131926616v2.jpeg "DASYLab: Seit dem 1. Juni 2026 wird die Messtechnik-Software exklusiv von measX angeboten. Emerson hat den Vertrieb vollständig übergeben. (Bild: mewsaX)")
:quality(80)/p7i.vogel.de/wcms/81/49/8149448d4ea33968a31dbdd25fc83b39/0131954942v2.jpeg "(Bild: HMS Technology Center GmbH)")
:quality(80)/p7i.vogel.de/wcms/1d/8c/1d8cf2cea3b1f2b03315a4a4ca03b8ec/0131908227v2.jpeg "Seok-Hee Lee, ehemals CEO von SK Hynix, nun Executive Vice President für Intels Advanced-Packaging-Sparte. Für den koreanischen Industrieveteranen ist es zudem eine Rückkehr zum amerikanischen Chiphersteller. (Bild: Intel)")
:quality(80)/p7i.vogel.de/wcms/ba/ae/baae0558079e61bdf9aec7292c98c965/0131909060v2.jpeg "High-NA-EUV-Anlage von ASML: High-End-Fertigungstechnologie des niederländischen Ausrüstungsherstellers soll trotz Exportverboten nach China gelangt sein. ASML weist die Vorwürfe zurück. (Bild: ASML)")
:quality(80)/p7i.vogel.de/wcms/44/ad/44ad8f8b18b29422f6e68bdc261397e1/0131904972v2.jpeg "Synopsys setzt auf systembewusstes Co-Design statt Overdesign. (Bild: Synopsys)")
:quality(80)/p7i.vogel.de/wcms/87/ce/87ce5ee92b2ec5de9cde1623d64b0720/0131974509v2.jpeg "Überangebot an Solarstrom: Die Intersolar 2026 steht im Zeichen intelligenter Stromspeicher. „Der Speicher ist ein ‚Zwilling der Photovoltaik‘“, sagt Carsten König vom Bundesverband Solarwirtschaft. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/a6/eb/a6ebeccaf9aeeba5c394ea3b97a21fe5/0131938098v2.jpeg "Keysight erweitert sein Photonik-Design-Ökosystem um das GlobalFoundries PDK. Damit ist es mögliich, photonisch integrierte Schaltungen und die Überprüfung der Leistung optischer Verbindungen in einer einzigen Umgebung zu simulieren. (Bild: Keysight)")
:quality(80)/p7i.vogel.de/wcms/4e/41/4e4159d1e93e67d47bd2f51a90691b23/0131548978v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/d6/ea/d6eac438c362c545cab42ef0f30bcfc0/0130136975v2.jpeg "Die Bewerbungsphase für den James Dyson Award 2026 ist gestartet. (Bild: Dyson)")
:quality(80)/p7i.vogel.de/wcms/e5/6c/e56ceb935ba09cb66a4fd0f961b2d3e9/0129642888v2.jpeg "(Bild: Vogel Professional Education)")
Anbieter zum Thema
Die richtigen Konzepte und Werkzeuge für den Erfolg
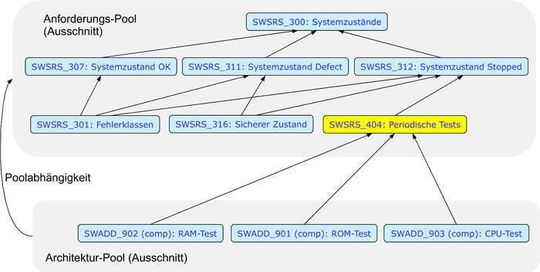
Um aus der Traceability diesen Mehrwert ziehen zu können sind ein schlüssiges Konzept und Automatisierung durch Werkzeugunterstützung Grundvoraussetzungen. Ein denkbares Konzept beruht auf einem Modell, dessen Gegenstände Elemente (auch Items genannt), Element-Pools, Element-Traces, Pool-Traces, Versionen von Elementen und Pools sowie Baselines und Releases sind.
- Elemente sind die kleinsten verfolgbaren Einheiten, z.B. einzelne Anforderungen oder einzelne Testfallspezifikationen. Sie sind durch einen eindeutigen Identifikator gekennzeichnet, einzeln versionierbar und tragen Workflow-Attribute, die ihren Status als „draft“, „stable“, „active“, „deleted“ etc. beschreiben.
- Pools (oft auch Module genannt) sind Zusammenfassungen von Elementen gleichen Typs, z.B. die Anforderungen zu einem bestimmten Teil eines Projektes. Pools sind ebenfalls durch Links miteinander verbunden. In sogenannten Baselines lassen sich Entwicklungsstände eines Pools versionieren.
Auf dieser Grundlage werden nun strukturelle und logische Regeln für die Konsistenz der Traceability erstellt, wie:
- Ein Element muss genau einem Pool angehören.
- Ein Pool-Link muss sich immer auf eine bestimmte Baseline oder den Head beziehen.
- Traces dürfen nur zwischen Elementen gezogen werden, die zu voneinander abhängigen Pools gehören. Dabei sind nur Traces erlaubt, die zu einem definierten Typ gehören, denn Traces drücken eine bestimmte Relation aus. Natürlich sind verschiedene Arten von Traces zwischen den gleichen Arten von Elementen erlaubt.
- Von einem Element mit Workflow-Status „deleted“ darf keine Trace zu einem Element mit Status „active“ führen.
- Ein Pool darf nicht freigegeben werden, wenn er von einem Pool abhängt, der nicht freigegeben ist.
- Ist ein Pool über verschiedene Pool-Traces von einem anderen Pool abhängig (z.B. hängt die Integrationstest-Spezifikation direkt und indirekt über die Architektur-Spezifikation von den Anforderungen ab, vgl. Abb. 1), dann müssen sich alle Wege auf die gleiche Baseline des referenzierten Pools beziehen. Bei einem ganzen Netz aus Abhängigkeiten ist gerade diese Anforderung nicht immer trivial.
Externer Traceability-Mechanismus schafft Verbindung
Hat man Modell und Regeln definiert, ist die wichtigste Arbeit im Grunde getan, denn man könnte das Modell durch Handarbeit implementieren. Damit die Traceability aber wirklich Spaß macht (und auch damit sie bezahlbar bleibt), muss ein möglichst hoher Automatisierungsgrad erreicht werden. Ein weiteres Ziel ist eine möglichst hohe Durchgängigkeit bei der Erstellung und Pflege der Traces. Diese Ziele, aber auch eine konsistente Integration mehrerer Entwicklungs-Tools, sind in der Regel nur mit Hilfe eines externen Traceability-Werkzeuges zu erreichen. Viele Werkzeuge unterstützen zwar innerhalb ihrer Grenzen die Traceability, scheitern jedoch daran, externe Elemente mit einzubeziehen.
Die beliebte Vorgehensweise, alle Arten von Elementen im Requirement Management Tool zu verwalten, weil es Traceability unterstützt, kann nicht als Lösung gelten. Denn entweder müssen Elemente wie Architektur-Beschreibungen oder Testfall-Spezifikationen mit Werkzeugen bearbeitet werden, die nicht dafür geeignet sind; oder man bearbeitet die Elemente, z.B. UML-Diagramme, in einem adäquaten Modellierungs-Tool und importiert anschließend die graphische Darstellung ins RM-Werkzeug. Das allerdings birgt die große Gefahr, dass bei Änderungen am Diagramm der Import vergessen und dadurch ein inkonsistenter Stand der Arbeit erreicht wird. Man stelle sich diese Vorgehensweise für Quellcode vor!
(ID:296369)
:quality(80)/p7i.vogel.de/wcms/cd/ef/cdefb246f644cb798b7db431a442bc29/0131777880v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/e3/cd/e3cdb56cb5074240359bd315ab9dc8cb/0129944242v4.jpeg "Die Schlagworte \"Ki-getrieben\" und \"Software-definiert\" stehen auch bei den führenden Herstellern von Test- und Debug-Werkzeugen für Mikrocontrollerbasterte Systeme eine zentrale Rolle. (Bild: Lauterbach)")